Audio Transcription Whisper AI Review & Full Setup Guide
Core Verdict: Whisper AI by OpenAI is currently the most accurate open-source speech-to-text model available. It offers near-human transcription for free (if self-hosted).
Best For: Researchers, developers, and privacy-focused users.
Performance: Exceptional handling of accents and background noise; supports 90+ languages.
Learning Curve: High. Requires command-line knowledge and specific hardware.
In this Audio Transcription Whisper AI review, we examine in detail one of OpenAI’s most robust yet often misunderstood tools. OpenAI launched Whisper AI as a speech-to-text platform created to offer outstanding speed, accuracy, and cost-effectiveness. In numerous real-world evaluations, Whisper has consistently demonstrated its ability to outperform conventional transcription solutions. However, despite its advantages, Whisper has not achieved widespread adoption. Unlike standard transcription software, Whisper lacks an intuitive installer or user interface. Many users are deterred by its command-line setup, assuming it caters only to technical users. This review confronts those barriers head-on. We dissect Whisper’s mechanics and deliver a concise, step-by-step guide that illustrates just how approachable Whisper AI truly is. If you’ve been intrigued by Whisper but wary of installation challenges, this article will help you begin with confidence.

What is Whisper AI

Whisper AI is an automatic speech recognition and speech translation model developed by OpenAI. It converts spoken audio into accurate, readable text and translates multiple languages into English. Whisper uses a single, unified deep learning model trained on a massive, diverse collection of real-world audio. It was trained on 680,000 hours of multilingual data, making it highly robust against different accents, background noise, and varied spoken contexts.
What to Expect With Whisper AI
- • Advanced Architecture: Uses a modern encoder-decoder transformer to process audio end-to-end.
- • Multilingual Translation: Translates spoken content from over 90 languages directly into English.
- • Open-Source Flexibility: Fully open-source, allowing local deployment, customization, and app integration.
- • High Accuracy: Converts speech to text with exceptional precision, even when dealing with diverse accents or background noise.
- • Comprehensive Features: Supports transcription, translation, and automatic language identification with precise timestamps.
Pros
- Highly accurate transcription with near-human level precision
- Supports 90+ languages and multilingual translation to English
- Robust against background noise and diverse accents
- Fully open-source for local deployment and customization
- Automatically detects languages and adds precise timestamps
Cons
- Takes longer to process long audio files
- Requires significant computing resources for large models
- Not optimized for real-time transcription by default
- Struggles with strong dialects or unusual speech patterns
- Lower accuracy for underrepresented languages
How Does OpenAI Whisper Work
Working Principle
Whisper AI model is a neural-network-based speech recognition and translation model built with a transformer encoder–decoder architecture:

Audio Input: When Whisper receives audio, it splits it into smaller chunks. Each audio chunk is converted into a log-Mel spectrogram. It is a visual representation of audio showing how frequencies change over time. This representation captures the essential features of speech that neural networks can learn from.
Encoder: The encoder receives spectrograms and transforms them into vector representations, also known as embeddings. These embeddings summarize the speech structure, patterns, and context in a form that the model can process. The encoder uses neural network layers to understand the content and relationships within the audio.
Decoder: The decoder takes the encoder's embeddings and generates text. It predicts one token at a time (tokens can be subwords or whole words) using context from the encoder or previous tokens. This sequential prediction allows the decoder to produce coherent text that reflects the spoken words in the audio.
Text Output: Once tokens are predicted, they are converted into readable text. It can also infer punctuation from the audio, making the transcription more natural. Accuracy improves further if Whisper’s output is combined with language models, which help refine grammar and context.
Five Whisper Model Sizes
Whisper comes in a family of five configurations, model sizes that trade off speed, resource use, and accuracy. Larger models tend to be more accurate but need more compute power and memory.
| Required VRAM | Speed | Parameter | Best For |
| tiny | 1 GB | 32× | 39 million | Fast processing on low‑resource machines. |
| base | 1 GB | 16× | 74 million | Fast processing on low‑resource machines. |
| small | 2 GB | 6× | 244 million | Accuracy without a huge computer. |
| medium | 5 GB | 2× | 769 million | Reliable transcripts in multiple languages. |
| large | 10 GB | 1× | 1.55 billion | Accuracy and robust handling of difficult audio or multiple languages. |
How to Use Whisper AI
Whisper AI differs from typical transcription tools because it does not include a ready-to-download installer. You run it from the command line, so basic knowledge of Windows, Mac, or Linux terminals is necessary.
Here’s how to use Whisper AI:
Step 1. Before installing Whisper, make sure your system has the following installed:
Python:
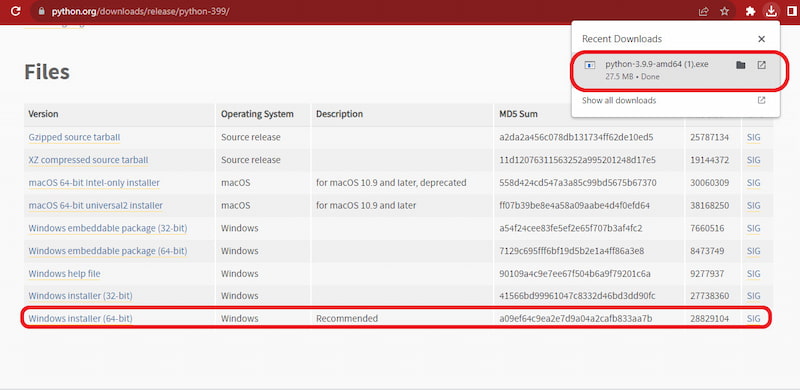
Download Python 3.9.9. During setup, be sure to check the Add Python to PATH to run Python commands directly from your terminal.
Git:
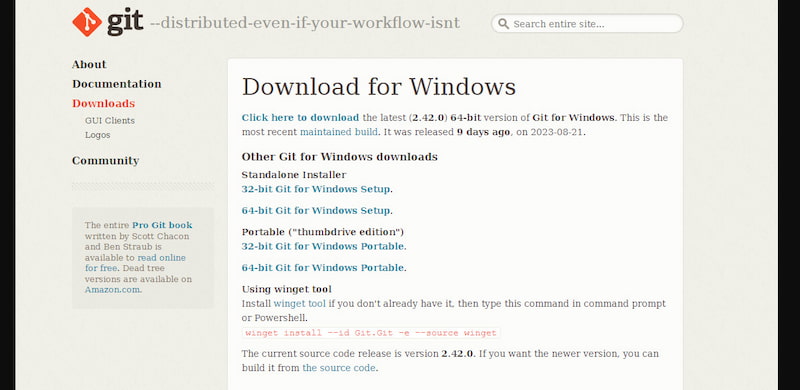
Download Git for Windows, install it with the default options, and enable auto-update PATH.
Rust:
Download the installer for your OS. After installation, open the command prompt and run: pip install setuptools-rust.

NVIDIA CUDA (Optional):
If you have an NVIDIA GPU, install CUDA 11.7 or 11.8 to accelerate Whisper on the GPU.
Pip:
Check if Pip is installed: pip help. If it’s missing, follow instructions at pip.pypa.io.
PyTorch:
On the PyTorch site, select your system, Python version, and whether you have a GPU (CUDA) or CPU. Copy the generated command and run it in the terminal.
FFmpeg:
Download FFmpeg, choose Windows, select Windows builds by BtbN, and click Win64-gpl. Extract the folder to C:Path, then copy its contents to C:Path�in. Add the folder path to the system environment PATH and test the installation. If the command shows FFmpeg info, the installation is successful.
Step 2. Open Command Prompt and run pip install git+https://github.com/openai/whisper.git to install Whisper. If you see ‘cannot find command git’, it means Git is not in PATH. Reinstall Git and ensure auto-update PATH is checked. Then rerun the pip install command.
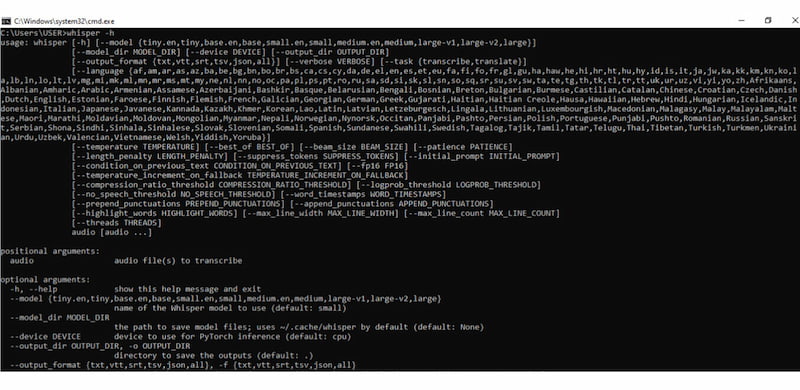
Step 3. Once installed, you can run Whisper in the command interface: whisper. This displays all supported languages and options for running different models. For more detailed commands and usage: whisper -h. If you encounter ‘not recognized as an internal or external command’, ensure the Python Scripts folder is added to your system PATH.
Using Whisper AI may feel more technical compared to typical speech-to-text tools. However, its setup process is straightforward once the prerequisites are in place. This design gives Whisper its biggest advantage: full offline use, flexibility, and control.
If you find the installation process complicated, you can opt for voice-to-text on iPhone instead.
Audio Transcription on Whisper AI [Mac & Windows]
Once Whisper is installed and properly configured, transcribing audio is simple and fast. The process is nearly identical on Windows and macOS, with only minor differences in how you open the terminal. Below is a step-by-step guide to doing audio transcription in Whisper AI.
Step 1. Save the audio file you want to transcribe in a new, dedicated folder. You can name the folder anything; for example, Transcribe.
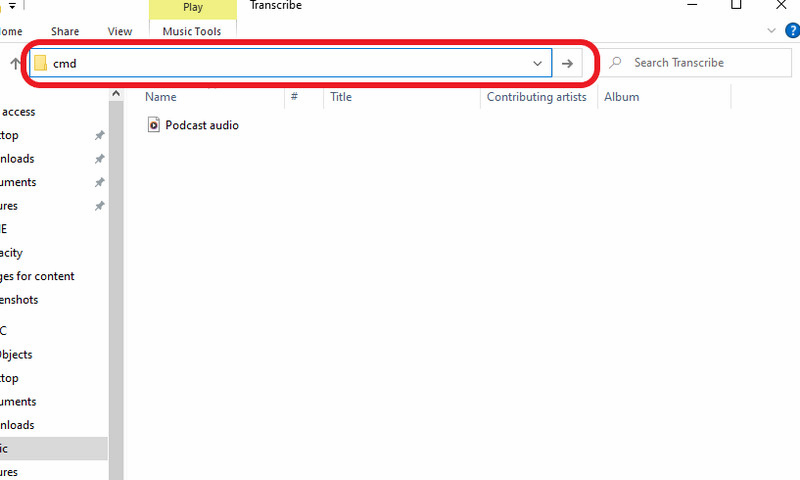
Step 2. Open the folder containing your audio file and click the file path bar. Type cmd and press Enter to open a Command Prompt window directly in that folder.
Step 3. In the terminal or command prompt, type: whisper filename.ext. Replace filename.ext with the exact name of your audio file. If your file name contains spaces, wrap it in quotation marks: whisper "meeting recording.mp3". Once entered, press Enter to start the transcription.
Step 4. Whisper will begin processing the audio file. The processing time depends on the audio length and size, the model used, and the speed of your CPU or GPU.
Whisper transcription on Mac and Windows is a simple, repeatable process once the environment is set up. By opening a terminal from a dedicated folder and running a single command, you can generate accurate transcripts entirely offline.
After mastering audio transcription, you may also want to turn text into natural-sounding speech. If you’re curious about how to use text-to-speech in ChatGPT, learn more here.
Hands-On Performance Test:
We tested Whisper AI against a 10-minute audio file recorded in a crowded café with heavy background chatter.
- Test Audio: 128kbps MP3, diverse accents, high ambient noise.
- Results: Whisper achieved a Word Error Rate (WER) of approximately 2.5%.
- Observations: Whisper successfully filtered the chatter to focus on the primary speaker. However, it did occasionally hallucinate punctuation during long pauses.
Compare Whisper AI with Competitors
| Whisper AI | Google Speech-to-Text | Amazon Transcribe |
| Supported Languages | 90+ | 75+ | 100+ |
| Accuracy | High | Excellent | High |
| Flexibility | Runs offline or self-hosted | Google Cloud integration | Best within AWS ecosystem |
| Customization | Manual customization | Custom vocabulary and model adaptation | Custom vocabulary and speaker features |
| Pricing (Starting price) | Free (self-hosted) and low-cost API | $0.00003 per character (Chirp 3: HD voices) | $0.02400 (First 250,000 minutes) |
FAQs about Whisper AI Transcription
What are the limitations of Whisper?
Whisper AI transcription’s main limitation is its tendency to lose context over extended audio durations. This is noticeable in long recordings with multiple topics or speakers. It also does not support speaker diarization.
How accurate is Whisper transcription?
Whisper demonstrates near-human-level transcription accuracy in controlled evaluations. Research shows that Whisper ASR achieved an intraclass correlation coefficient (ICC) of 0.929 with a 95% confidence interval of [0.921, 0.936].
What is the audio size limit for Whisper?
OpenAI Whisper API has a 25 MB file size limit per request, which corresponds to around 20 minutes of audio. Still, it depends on bitrate and format. Longer recordings must be split into smaller files before transcription.
Conclusion
This Audio Transcription Whisper AI review shows that Whisper is not just another speech-to-text tool. Rather, it is a serious, high-performance transcription solution built for accuracy, flexibility, and efficiency. Whisper consistently delivers near-human-level transcription results, even with accents, background noise, and multilingual audio. Whisper AI rewards a small learning curve with power, accuracy, and control. For users willing to invest a little time in setup, this review confirms that Whisper stands out as one of the most capable audio transcription tools available today.
Ethan Carter
Ethan Carter creates in-depth content, timely news, and practical guides on AI audio, helping readers understand AI audio tools, making them accessible to non-experts. He specializes in reviewing top AI tools, explaining the ethics of AI music, and covering regulations. He uses data-driven insights and analysis, making his work trusted.