What is Automatic Speech Recognition and How Does it Work
SUMMARY:
Definition: Automatic Speech Recognition (ASR) is a subset of AI that converts acoustic signals into machine-readable text using neural network architectures.
Current Standard: Modern systems have moved from hybrid HMM-GMM models to End-to-End (E2E) Transformers, drastically reducing Word Error Rates (WER).
Top Models: Leading 2026 frameworks include OpenAI Whisper v3, Deepgram Nova-2, and Nvidia Canary.
Automatic Speech Recognition is a groundbreaking technology that allows computers and devices to understand and convert human speech into written text. Today, ASR plays a key role in making interactions with technology more natural and efficient. It powers voice assistants, speech-to-text tools, automated customer service systems, and real-time transcription, enabling faster communication and greater accessibility.
This post covers the fundamentals of Automatic Speech Recognition technology. You will learn how ASR works, explore its key use cases and applications, and understand the current challenges it faces. Additionally, we will take a look at the future of speech recognition, specifically the end-to-end deep learning models. The aim of this post is to give you a clear and comprehensive understanding of ASR, from its basic principles to its real-world impact and future potential.

What is Automatic Speech Recognition (ASR)?
What is Automatic Speech Recognition?
Short for ASR, it is a subset of AI that enables computers to transform spoken words into written text. The process begins by analyzing audio signals and breaking them into smaller sound units. ASR then utilizes machine learning models to match those sounds with words and phrases based on learned speech patterns, accents, and pronunciation variations. Today’s ASR systems leverage deep learning and massive speech datasets to deliver fast, reliable, and near-human-level transcription. This technology is widely integrated into tools we interact with daily, such as Siri, Google Assistant, Alexa, and various speech-to-text dictation software.
Important Note: ASR is different from Natural Language Processing (NLP). ASR’s primary goal is speech-to-text conversion, while NLP focuses on understanding, analyzing, and generating language in written form. Together, they often work within larger AI systems.
How ASR Technology Works
After understanding the definition of ASR, let us now further explore how it works. At its core, ASR converts raw speech into text by analyzing sound signals and predicting meaningful word sequences. This process mainly relies on two key components: acoustic modeling and language modeling, which work together to achieve accurate speech-to-text results.
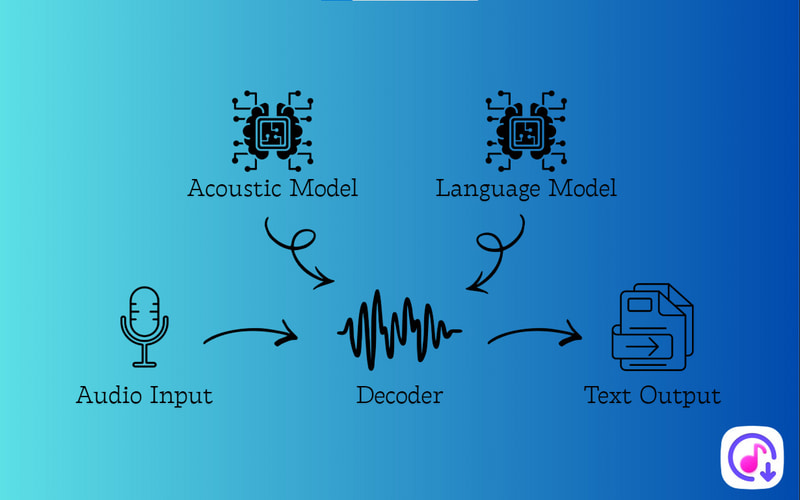
Acoustic Modeling
Acoustic modeling focuses on how speech sounds are produced and represented as digital signals. When a person speaks, the ASR system captures the audio and extracts key features such as frequency, pitch, and timing. It is traditionally built using techniques such as Hidden Markov Models (HMMs) and Gaussian Mixture Models (GMMs). These models learn the relationship between audio features and phonemes (the basic units of speech). They analyze natural variations in pronunciation, accent, and speaking speed, allowing the system to accurately identify which sounds are being spoken at any given moment.
One example is ChatGPT’s OpenAI Whisper model. It uses sophisticated Automatic Speech Recognition (ASR) that incorporates acoustic modeling to convert speech into text. Learn here how can ChatGPT transcribe audio into accurate text instantly.
Language Modeling
Language modeling determines how words are organized to form meaningful sentences. Since similar sounds can represent different words, acoustic analysis alone is not enough. A language model uses statistical methods to estimate the probability of word sequences based on grammar rules and real-world language usage. It helps the Automatic Speech Recognition technology choose the most logical word order from multiple possibilities. This ensures the final transcription makes sense in context. By combining linguistic patterns with probability analysis, language models greatly improve accuracy.
In 2026, the biggest leap in ASR accuracy came from LLM-assisted Decoding. Rather than just predicting the next sound, the system uses a Large Language Model to understand the intent. For example, if you say The sun is too bright, the model knows to choose sun over son because the surrounding context (bright) makes son statistically improbable.
To evaluate the effectiveness of an ASR system, engineers track two primary metrics: Word Error Rate (WER) and Real-Time Factor (RTFx):
| Avg. WER (%) | Latency (RTFx) | Best Use Case |
| Legacy Hybrid | 12% – 18% | 0.8s – 1.2s | Offline static transcription |
| Whisper (E2E) | 7% – 9% | 0.3s – 0.5s | Multilingual translation |
| Streaming ASR | 9% – 11% | < 0.1s | Live Captions / IVR |
| SOTA (Canary) | < 6% | 0.2s | High-stakes medical/legal |
Key Use Cases and Applications
ASR has become an essential part of modern digital experiences. It helps businesses and individuals save time, improve accessibility, and interact with technology more naturally. Let’s move forward to the use cases of ASR and explore how it is applied in real-world scenarios.
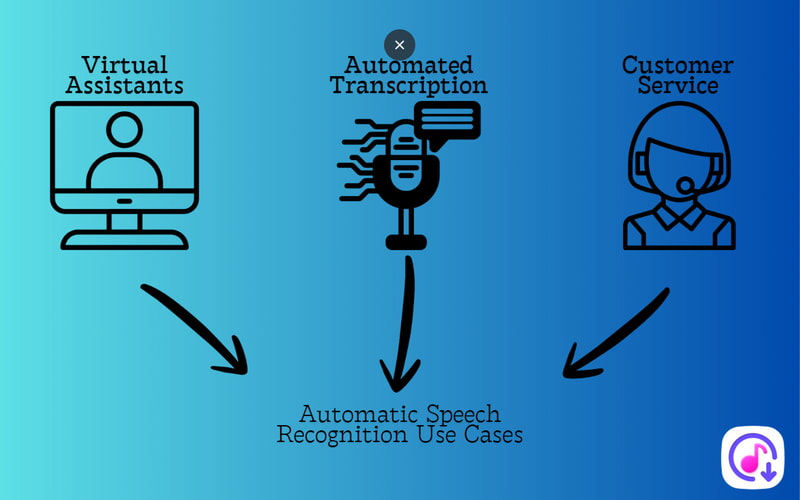
Virtual Assistants
Virtual assistants rely on ASR to interpret spoken commands and respond accurately. When a user interacts with Siri or Alexa, the ASR engine converts their voice into text for the system to process. This hands-free interaction improves convenience and accessibility, particularly for those who prefer voice control or have physical limitations that make typing difficult.
Automated Transcription
Automated transcription tools use speech-to-text algorithms to transform spoken dialogue into written records. Platforms like Otter.ai and Zoom utilize ASR to provide real-time captions and transcripts for meetings, lectures, and interviews. These searchable text records are invaluable for note-taking, content creation, and ensuring accessibility for individuals with hearing impairments.
Most ASR models run on computers, but did you know your iPhone can turn voice to text, too?
Customer Service
In the customer service sector, ASR powers Interactive Voice Response (IVR) systems that manage incoming calls. By recognizing spoken responses, these systems can route calls, answer FAQs, or complete routine tasks without the need for a human agent. This improves operational efficiency, reduces wait times, and allows businesses to offer 24/7 support.
Current Challenges in ASR
A new challenge for 2026 End-to-End models is hallucination. Because modern ASR models predict the next word based on context, they may sometimes insert words that weren't actually spoken if the background noise is too high. Professional ASR workflows now include a Confidence Score for every word, flagging potential errors for human review.
Despite major advances in the ASR model, many systems still face limitations in real-world use. Most ASR solutions struggle with at least one core issue, especially when speech conditions are less controlled. Variations in how people speak, environmental factors, and complex conversations continue to challenge accuracy and reliability. Below are some of the most common challenges in ASR today.
Accents and Dialects
Accents and dialects are a major challenge for ASR because speech patterns vary widely across regions and cultures. Differences in pronunciation, intonation, and word usage can cause the system to misinterpret spoken words. Many models are trained on limited or unbalanced datasets, which means they often perform better with standard or widely used accents. As a result, users with strong regional accents may experience lower transcription accuracy.
Background Noise Environments
ASR performance often drops in noisy environments such as busy streets, offices, or public places. Background sounds like music, traffic, or overlapping voices interfere with the system’s ability to isolate the main speaker’s voice. Even advanced noise reduction techniques cannot fully remove unwanted audio in all situations. This makes it difficult for ASR to accurately capture speech, especially in real-time applications like calls or live captions.
Speaker Diarization
Speaker diarization is the ability of an ASR to identify and separate speakers in a conversation. This is challenging in meetings, interviews, or group discussions where multiple people speak, interrupt each other, or have similar voices. Without accurate diarization, transcripts may fail to show who said what, reducing clarity and usefulness. Improving speaker detection and separation remains an ongoing challenge in multi-speaker ASR systems.
Future: End-to-End Models
Modern Automatic Speech Recognition systems are increasingly built on end-to-end (E2E) deep learning models. These architectures transform speech processing from a multi-step pipeline into a single, unified neural network. Rather than relying on separate acoustic, phonetic, and language models, E2E systems learn to map audio signals directly to text. This integration reduces system complexity, lowers latency, and improves overall accuracy. Furthermore, by training on massive datasets, these models can learn rich speech representations from unlabeled audio through self-supervised learning, which are then fine-tuned to achieve exceptionally low Word Error Rates (WER).
Current architectures, such as sequence-to-sequence (seq2seq) models, utilize an encoder to capture context from input audio and a decoder to generate text autoregressively. Advanced designs, including Transformers and Recurrent Neural Networks (RNNs) such as LSTMs, enable these models to better capture long-range dependencies and complex speech patterns. Consequently, E2E ASR systems offer faster development cycles and robust multilingual support, establishing them as the industry standard for the future of voice technology.
Key Components and Concepts of End-to-End Models:
Encoder: Processes the raw input audio and converts it into a compact vector representation. This captures essential acoustic features and contextual information, which is then passed to the decoder.
Decoder: Generates the output text sequence by predicting tokens step-by-step. It utilizes the encoder’s context and its own previous outputs to maintain linguistic coherence.
Transformers: These utilize self-attention mechanisms to process audio frames in parallel. This allows the model to capture long-range dependencies more efficiently than previous methods, significantly boosting transcription accuracy.
Recurrent Neural Networks (RNNs): Utilizing variants like LSTMs, RNNs process data sequentially. They are naturally suited for speech because they maintain a hidden state that remembers previous elements in the sequence to inform current predictions.
By unifying the speech-to-text process into a single network, E2E models eliminate the need for hand-engineered components. This results in reduced complexity, lower latency, and scalability.
Conclusion
Automatic Speech Recognition has become an essential technology in today’s digital world. It transforms the way we interact with devices and access information. From powering virtual assistants to enabling real-time transcription and improving customer service, ASR is making communication faster, more efficient, and more accessible. While there are challenges, advances in modern end-to-end deep learning models are pushing the boundaries of accuracy and performance. By understanding how ASR works, its applications, and its current limitations, we can appreciate its impact and anticipate the exciting innovations ahead in speech recognition.
Ethan Carter
Ethan Carter creates in-depth content, timely news, and practical guides on AI audio, helping readers understand AI audio tools, making them accessible to non-experts. He specializes in reviewing top AI tools, explaining the ethics of AI music, and covering regulations. He uses data-driven insights and analysis, making his work trusted.